ByteDance's Latest Thinking Model, Seed-Thinking-v1.5 Technical Details Disclosed
ByteDance's Latest Thinking Model, Seed-Thinking-v1.5 Technical Details Disclosed
Date
2025-04-14
Category
Technology Launch
ByteDance Seed has released the technology report for its latest thinking model, Seed-Thinking-v1.5 , covering explorations in data systems, reward models, RL algorithms, infrastructure and other dimensions:
- Enhanced reasoning through refined data processing, blending verifiable and non-verifiable data, and introducing a new set of benchmarks;
- Dual-track reward system, using intelligent logic verification for verifiable tasks and pairwise comparison optimization for non-verifiable tasks, enabling precise training across mathematical reasoning and creative generation;
- Improved the reasoning limit of large language models through accurate data construction in the SFT stage and key algorithm innovations in the RL stage.
- Optimized HybridFlow programming model and streaming reasoning system, and supports tensor/expert/serial three-layer parallel architecture.
Seed-Thinking-v1.5 is an upcoming intelligent reasoning model from the ByteDance Seed team. The model excels in specialized fields such as mathematics, programming, scientific reasoning, and general tasks such as creative writing. The model adopts the MoE architecture, with a total parameter of 200B and an activation parameter of 20B, and has a significant cost advantage in reasoning.
The technical report of Seed-Thinking-v1.5 is now public, and the API will be available for user testing via Volcano Engine starting April 17.
Technical Report Link: https://github.com/ByteDance-Seed/Seed-Thinking-v1.5
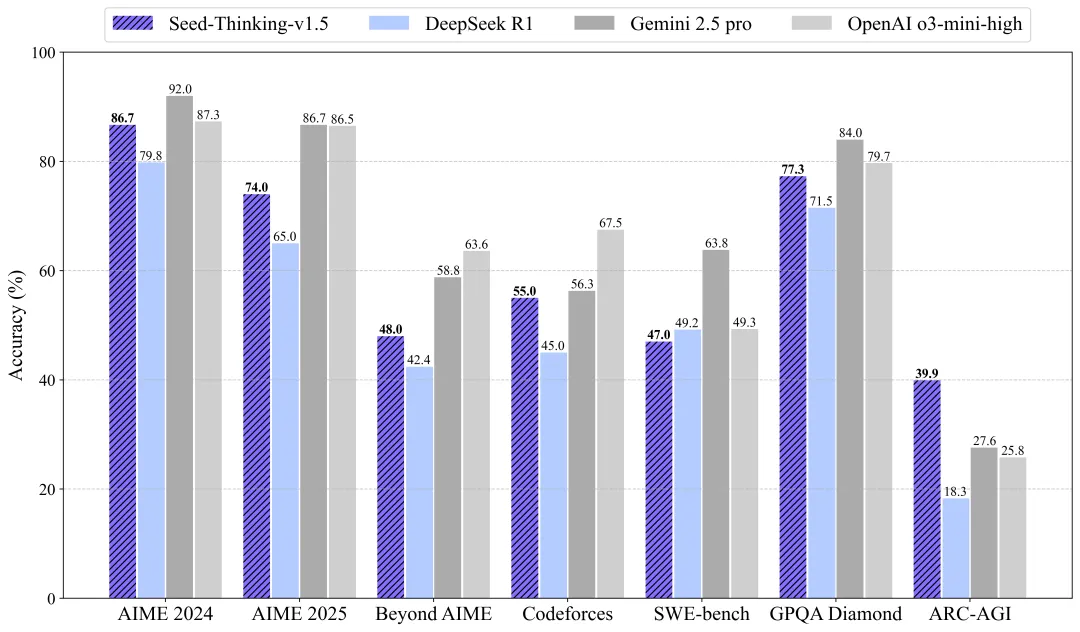
Seed-Thinking-v1.5 Performance
Below are the model's key benchmarks, compared against selected industry-leading models such as o3, R1, Gemini 2.5 Pro for reference.
- Areas of Expertise: Mathematical reasoning (AIME 2024 score of 86.7, catching up with OpenAI o3-mini-high), programming competition (Codeforces pass@8 score of 55.0%, close to Gemini 2.5 Pro), scientific reasoning (GPQA score of 77.3%, close to o3-mini-high), all of which reached or were close to the first echelon level in the industry.
- Generic Tasks: Human evaluation performance exceeded DeepSeek R1 by 8%, covering multi-scenario requirements.
- Cost Advantages: The unit reasoning cost is reduced by 50% compared by DeepSeek R1, balancing between performance and efficiency.
A Deeper Dive from Data, RLto Infra
1. Data System: Fusing Verifiable and Creative Data
For the different needs of reasoning and generative tasks, the team optimized the data processing strategy:
- Verifiable Data (e.g. mathematics and code questions): Triple-cleaned (human review → model filtering → multi-model verification) from millions of samples, retaining 100K high-difficulty problems. Integerized answers and offline sandbox validation ensure step-by-step reasoning.
- Non-verifiable Data (e.g. creative writing): Based on the Doubao 1.5 Pro training set, low-value samples were excluded, and the two-way reward method was used to optimize the generation quality.
- New Benchmark: Built BeyondAIME (100 unanswered stem questions), an ultra-hard math dataset, to solve the problem of inadequate differentiation of existing tests.
2.Reward Model: Dual-track system calibration training direction
The team innovatively proposed a dual-track reward system that balances the tasks of "right and wrong" and "Opinions vary":
- Verifiable Tasks: Developed two generations of validators (Seed-Verifier→Seed-Thinking-Verifier) to upgrade from character matching to line-by-line comparison of reasoning steps (training/test set accuracy rate exceeds 99%) to eliminate the model from "reward deception".
- Non-verifiable Tasks: Introduced pairwise contrast training, through tens of millions of "AB tests", to capture the hidden human preferences for creativity, emotion, etc., to avoid "one-size-fits-all".
- Dual-track Fusion: Designed a coordination mechanism for mixed scenarios, where hard indicators (rights and wrongs) and soft preferences (goods and bads) complement each other to support full-scenario training.
3. Training Method: "Supervised Fine Tuning + Reinforcement Learning" two-stage optimization
Seed-Thinking-v1.5 adopts the Full-Link training of "Laying the foundation + Grinding capabilities":
- Supervised Fine Tuning (SFT): **Based on 400,000 high-quality instances (300,000 verifiable + 100,000 non-verifiable data), combined with artificial and model collaborative screening, a long thought chain dataset is constructed to ensure that the model "thinks like a human".
- Reinforcement Learning (RL): Through a triple data engine (verifiable/generic/hybrid data), algorithmic innovations (value pre-training, decoupled GE, etc.) and online data adaptation technologies to solve problems such as training instability, long-chain reasoning faults, and dynamically adjust the data distribution to maintain optimal training state.
4. Training Framework: The underlying architecture supporting 20B MoE
To address the complex training needs of 20B MoE (total parameter 200B), the team optimized the underlying architecture:
- HybridFlow Programming Model: Support algorithm rapid exploration and distributed parallel operation.
- Streaming Reasoning System (SRS): By decoupling model evolution and asynchronous reasoning through "Streaming Reasoning" technology, training speed is increased by 3 times, and stability is 95% under trillion parameters.
- Three-layer parallel architecture: Combine tensor/expert/serial parallelism with dynamically balanced loading to optimize GPU power utilization based on the KARP algorithm.
Seed-Thinking-v1.5 hopes to push the reasoning model from "special" to "generic" through deeper technical exploration, and achieve breakthroughs in efficiency and scene coverage (from mathematics competitions to creative writing).
The team is about to make the BeyondAIME benchmark public, facilitating industry technology iteration, and will make the Seed-Thinking-v1.5 interface available to users via the Volcano Engine.
Final Thoughts
True intelligence begins with "thinking like a human". The increase in reasoning is just a small step in LLM's journey to intelligence.
We look forward to the future of AI not just the code on the screen, but a "thinker" that will pause, associate, and actively share with you.
In the future, the Seed team will continue to pursue the upper limit of intelligence, while constantly exploring new interactions, so that AI can respond to real needs in a more natural and humanistic way, and take root in the real world, becoming the driving force for the advancement of human society and the upgrading of life experience.
The ByteDance Seed team has always been aiming to explore the endless boundaries of intelligence and unlock the infinite possibilities of universal intelligence.